Table of Contents Show
Abstract
Effective climate change communication requires inclusive, linguistically representative datasets to ensure equitable access to climate-related knowledge. In Nigeria, a multilingual and multi-ethnic nation home to over 500 languages, climate information is often disseminated primarily in English, systematically excluding large segments of the population, especially those with limited English proficiency or literacy. As climate change increasingly impacts indigenous and low-resource language communities, the need for localised, culturally relevant climate messaging grows more urgent. Yet, existing multilingual natural language processing (NLP) and machine translation systems lack the domain-specific accuracy and contextual sensitivity required for such high-stakes communication.
Our work responds by presenting a parallel climate messaging dataset in English and Nigeria’s three major indigenous languages (Yoruba, Igbo, and Hausa). It contains over 700 climate-related messages, including themes like rainfall warnings and flood risks. Multilingual sentence embeddings were generated using XLM-RoBERTa, followed by K-Means clustering to examine cross-linguistic patterns. Exploratory clustering across language pairs (Igbo-Yoruba, Hausa-Yoruba, Hausa-Igbo) showed observations consistent with linguistic typology regarding language families. This work advances climate adaptation efforts while also laying the groundwork for developing similar datasets in other low-resource Nigerian and African languages, promoting greater linguistic inclusivity in climate resilience initiatives.
Keywords: climate messaging, NLP, machine translation, indigenous languages, parallel dataset
Introduction
In many African countries, including Nigeria, indigenous language speakers face growing threats from extreme weather events, often without access to early warnings or critical safety information. With climate alerts typically issued in English, millions are excluded, making the need for inclusive, localised communication increasingly urgent (Oramah, Ngwu, and Odimegwu 2025).
Nigerian languages are often classified as low-resource (Nekoto et al. 2020) and lack domain-specific corpora in critical fields such as climate communication. While advances in African natural language processing (NLP) have improved tasks like named entity recognition (Adelani et al. 2021) and sentiment analysis (Muhammad et al. 2022), efforts have largely focused on general applications, leaving a gap in resources for lifesaving, localised climate alerts. This paper addresses that gap by developing a parallel corpus of climate-related messages in Hausa, Yoruba, and Igbo, three of Nigeria’s most widely spoken languages.
Methodology
The methodology follows these steps:
1. Data Collection and Curation: A 715-sentence dataset of climate alerts was compiled, focusing on key categories such as rainfall warnings, flood risks, and so on. English source texts were crafted and translated by native speakers (the authors), with external reviewers assessing cultural and linguistic appropriateness.
2. Preprocessing: All texts were cleaned and standardised using Python, removing inconsistencies in punctuation, spacing, and formatting. Basic checks ensured translations remained semantically faithful to the original English.
3. Model selection and Embedding Generation: This was required to perform analysis on the created dataset. XLM-RoBERTa was selected for this task as it outperformed AfriBERTa and LaBSE in clustering and qualitative analysis, which were performed on the embeddings generated from each model.
4. Unsupervised Clustering: To explore structural and topical similarities across languages, K-Means clustering was applied to the sentence embeddings with a K=2 value. Pairwise comparisons (e.g., Igbo-Yoruba, Hausa-Yoruba) were analysed visually and statistically to observe language alignments and divergences.
5. Visualisation: Dimensionality reduction techniques (PCA) were used to visualise clustering outputs. These plots offered insight into which language pairs exhibited higher structural similarity in the climate messages.
Ethical considerations
To ensure linguistic accuracy and cultural sensitivity, the Hausa, Yoruba, and Igbo translations were produced by native translators (the authors) and reviewed externally by other native speakers. The dataset will be released under an open license to promote inclusivity and broader access for researchers, developers, and policymakers working to reach non-English-speaking communities. Clear documentation of the dataset’s scope and limitations is also provided to support responsible use and highlight the urgent need for greater investment in Nigerian NLP and climate communication resources.
Findings
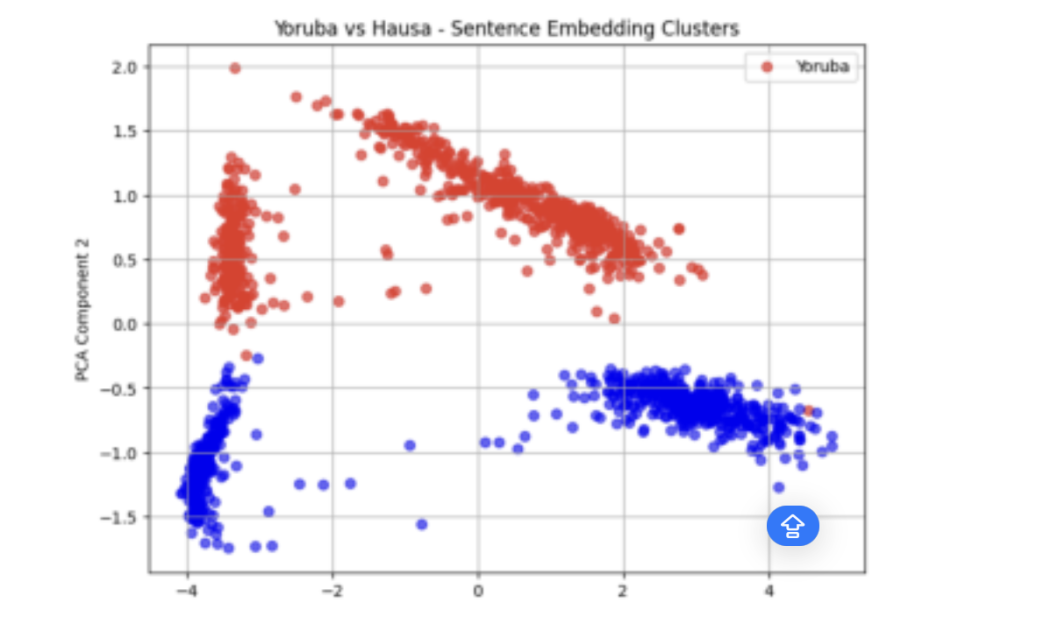
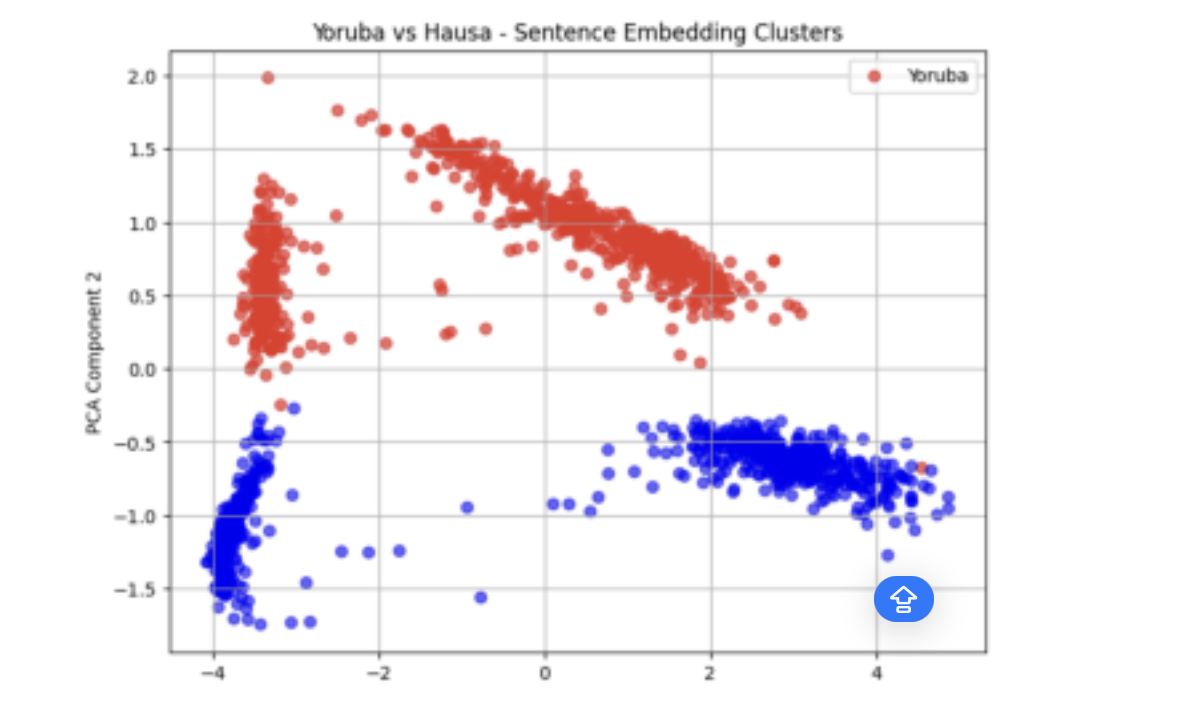
Exploratory clustering analysis on the generated sentence embeddings (from XLM-RoBERTa), using Principal Component Analysis (PCA), revealed patterns in how the climate-related messages are structured across the three languages. Visualisations of the embeddings showed that Yoruba and Igbo translations tended to form clusters in closer proximity, suggesting a higher degree of structural similarity. In contrast, Hausa messages often appeared more distant from both, indicating divergence in sentence construction or lexical choice. Figures 1,2,3, and 4 show these results.
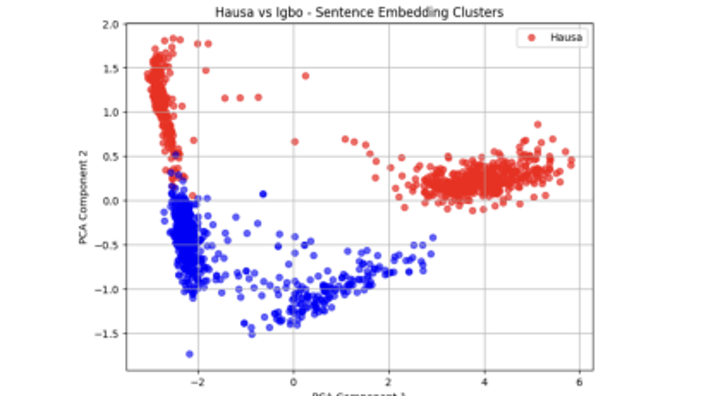
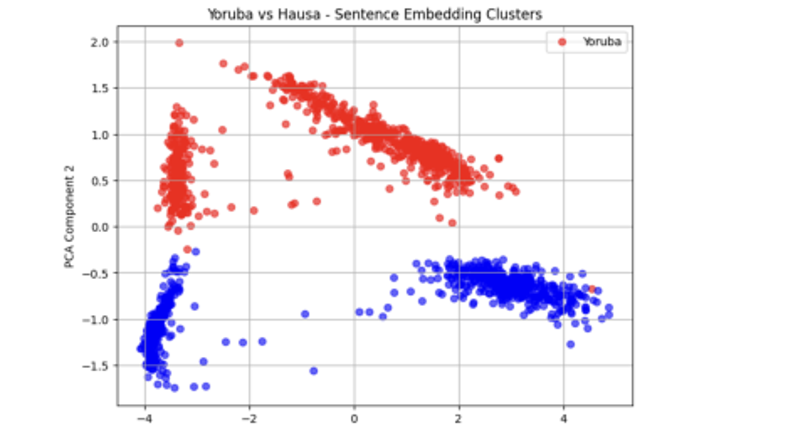
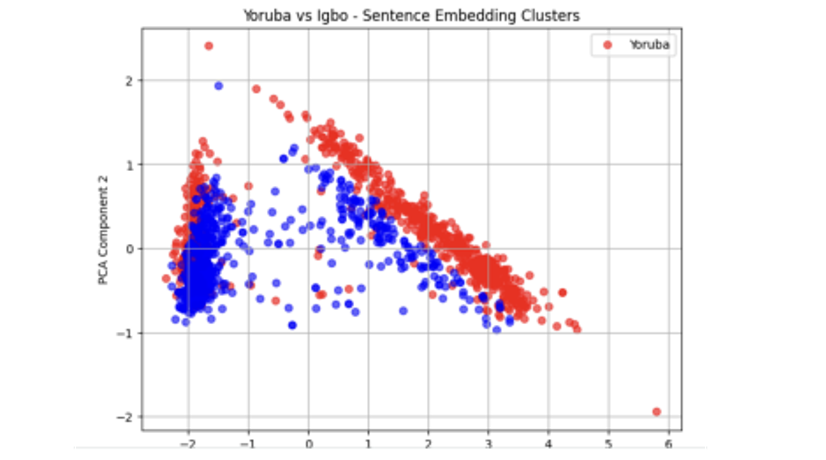
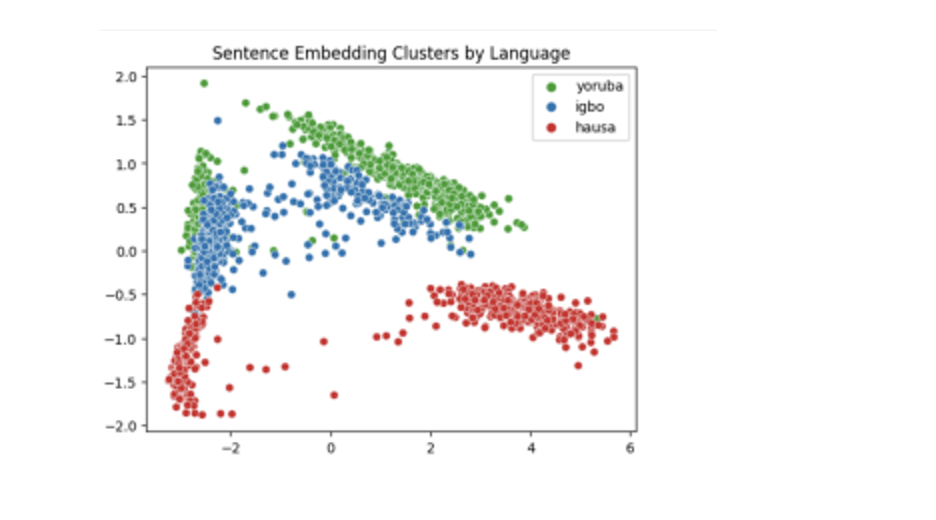
This observation aligns with linguistic theory: Yoruba and Igbo are both Niger-Congo languages, while Hausa belongs to the Afroasiatic family. These typological differences likely influence how even concepts such as weather events and safety instructions are encoded. Also, all sentences were ultimately grouped into two primary clusters despite structural differences, suggesting shared semantic themes or the influence of dataset construction choices.
Interdisciplinary implications
This work operates at the intersection of artificial intelligence, linguistics, disaster risk reduction, and public policy. From a linguistic standpoint, it shows the feasibility of applying AI tools to indigenous languages for socially impactful use cases, such as early warning systems. In climate adaptation and public communication, the dataset offers a localised tool that enables government agencies and civic technology developers to send alerts in the dominant languages of Nigeria. From a policy perspective, this work suggests that open, multilingual climate datasets should become part of Nigeria’s national disaster preparedness strategy. For education and research, this dataset can serve as a resource for research and discussion in computational linguistics, AI ethics, and applied machine learning within and outside Nigeria.
Conclusion
This study presented the development of a parallel climate messaging dataset in Nigeria’s three major indigenous languages as a step toward addressing the digital language gap in climate communication. While the dataset is limited in size and scope, it lays the foundation for more inclusive, localised climate communication systems and future research on climate adaptation tools.
Acknowledgements
We gratefully acknowledge the invaluable support of our mentors, Olanrewaju Samuel and Dr Abiodun Modupe, and the Research Round team for providing the platform and community to pursue this work.
References
Adelani, David Ifeoluwa, Jade Abbott, Graham Neubig, Daniel D’souza, Julia Kreutzer, Constantine Lignos, Chester Palen-Michel, et al. 2021. “MasakhaNER: Named Entity Recognition for African Languages.” arXiv.Org. March 22, 2021. https://arxiv.org/abs/2103.11811.
Muhammad, Shamsuddeen Hassan, David Ifeoluwa Adelani, Sebastian Ruder, Ibrahim Sa’id Ahmad, Idris Abdulmumin, Bello Shehu Bello, Monojit Choudhury, et al. 2022. “NaijaSenti: A Nigerian Twitter Sentiment Corpus for Multilingual Sentiment Analysis.” ACL Anthology. June 1, 2022. https://aclanthology.org/2022.lrec-1.63/.
Nekoto, Wilhelmina, Vukosi Marivate, Tshinondiwa Matsila, Timi Fasubaa, Tajudeen Kolawole, Taiwo Fagbohungbe, Solomon Oluwole Akinola, et al. 2020. “Participatory research for low-resourced machine translation: a case study in African languages.” arXiv.Org. October 5, 2020. https://arxiv.org/abs/2010.02353.
Oramah, Chinwe P., Tochukwu A. Ngwu, and Chinwe Ngozi Odimegwu. 2025. “Addressing the Impact of Complex English Use in Communicating Climate Change in Nigerian Communities Through Contextual Understanding.” Climate 13 (3): 56. https://doi.org/10.3390/cli13030056.